
“We have just launched our newest large language model trained with the best curated dataset with the state-of-the-art GPUs and we have improved on the MMLU by n number of points, surpassing the previous best.” Does this sound familiar? Reads like a press release of an AI company releasing their shiny new LLM for the world. As the arms race heats up it was bound to happen. But there’s one big problem with this line. No, I’m not talking about the obvious x-risk with larger, uninterpretable, and unaligned models. I’m not talking about the effects on climate change due to the the emissions of data centres. I want to illustrate one issue that’s not talked about as much but is actually much easier to control and to take action on.
I’m talking about benchmarks and evals. And I want to start with the elephant, or rather the whale in the room. The MMLU. It is treated as the gold standard of LLM benchmarks. Whenever a company releases their newest offering they boast about how much they have improved on it. Its almost as if getting a 100 means we have achieved AGI. But that’s far from the truth. Look at the following questions: 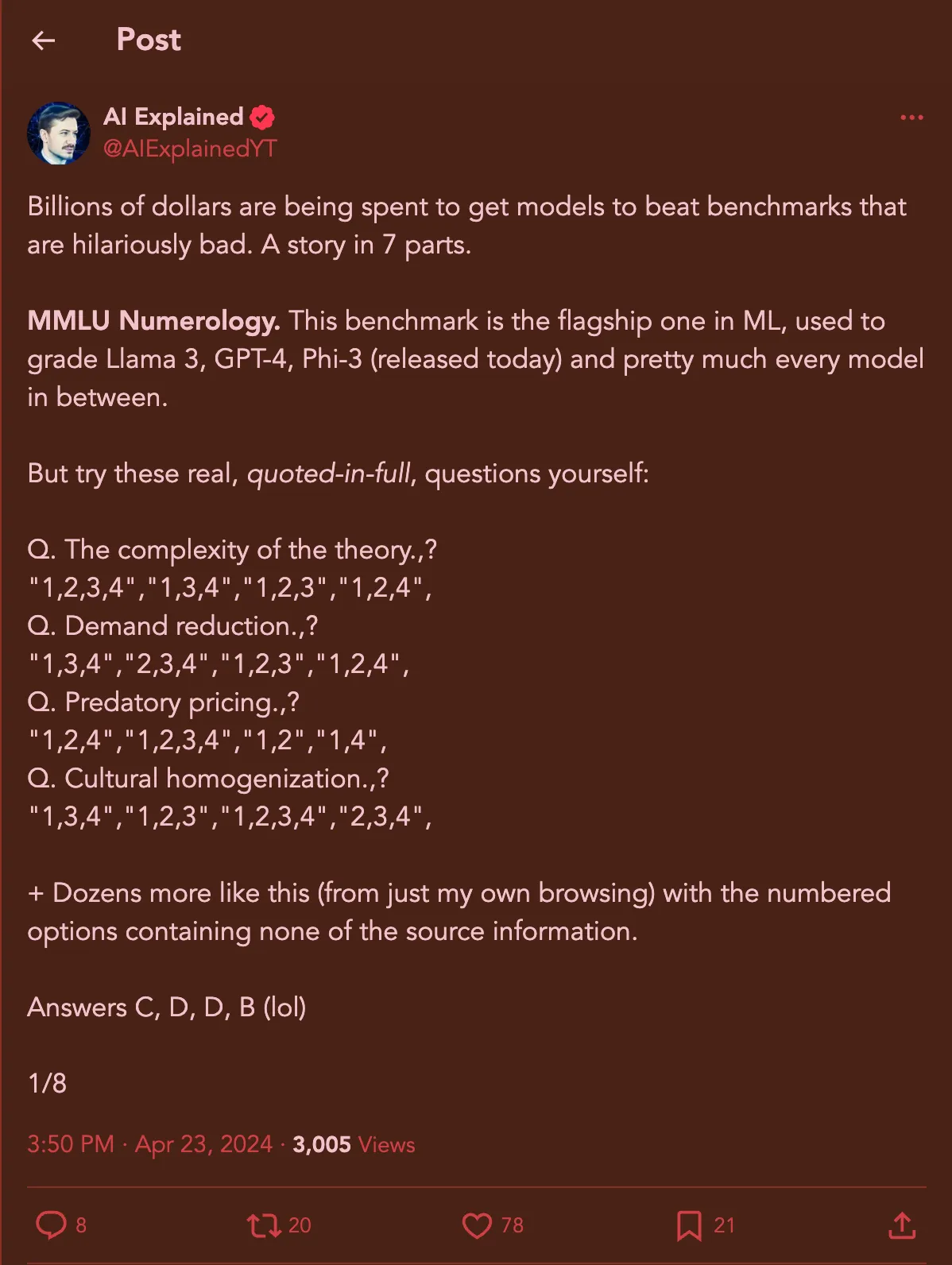
Do they make sense? At all? These are questions directly from the business ethics section of MMLU. You can go to huggingface right now and see for yourself. And this is only the tip of the iceberg. There was a recent paper that tested LLM performance on grade school math using the GSM8K dataset which is another common benchmark, and they found glaring errors in it [1]. From the same twitter thread above you’ll see that even other benchmarks like Hellaswag and CommonsenseQA have these problems.
Challenge of Picking an LLM
Picking the right language model for your project can be tricky, and benchmarks have an obvious problem of reliability. But they are often the first line of evaluation when organisations or individuals decide which LLM to use in their workflows and products. The downstream effects of this unreliability can be catastrophic. Just as an example, imagine you are a company deploying an assistant for grade-school students to practice math. You evaluate your LLM-based agent on GSM8K, and it works really well, reaching state-of-the-art performance. Hence, you gladly deploy it to hundreds of students. At the end of the semester your inbox is flooded with parents' emails saying their child has performed worse than before, and not remotely close to the performance numbers your marketing material claimed. Loss of reputation and lawsuits would soon become your day-to-day instead of improving your product further.
While there are general rules-of-thumb, like use the Cohere models for RAG, or integrate Snowflake’s new LLM for enterprise tasks, or utilise the Dolphin models if you need an uncensored assistant, these are all qualitative heuristics. Vibes can only take you so far. The world of choosing the LLM of choice is not as straight forward as going to the benchmark leaderboard and seeing how well it does in one that fits the bill. Firstly, the domains are vast, and benchmarks right now, are much more general. Sure there are a few specific ones for Medicine or Law or other domains, but on the whole we just don’t have enough of them. Secondly, the complexity of workflows, and the language required to capture it. Put simply, in most use-cases you don’t just do question -> answer pairs. There are often chains or multiple in-between steps (chain-of-thought, ReAct, etc.) that also need to be evaluated, which benchmarks don’t really cover. So the real world performance gets harder to judge. Third, prompt-LLM fit is a real thing, and further obfuscates results. How you prompt an LLM can drastically change its performance on benchmarks [3,4]. There’s no simple way of measuring how different formats of prompting will affect performance. Add to that, many organisations won’t share their system prompts which allowed them to get their advertised benchmark scores. And finally, there’s the whole can of worms of evaluating multimodal LLMs. Benchmarks are few, and the use-cases where they are applicable are overwhelmingly large. Oh and the hallucinations in this case seem even more terrible.
At this point you may be scratching your head and going, “well, how the heck do I pick an LLM then?” Well, there’s a short answer, and then there’s a long answer. The short answer is to use a few reliable benchmarks such as the GSM1K that was created by the same researchers who found the errors in GSM8K [1]. Novel, synthetically generated benchmarks, which are also human evaluated, such as these are available. Although they are rarer than a Grok-1 finetune. Another reliable “benchmark” is the LMSys Chat Arena, where human evaluators do 1-v-1 comparisons between different LLMs. The human evaluation aspect gives a much more realistic grounding in the results. Unfortunately these human-based evaluations are not scalable especially for smaller organisations, which brings us to the long answer.
The real world needs evals…
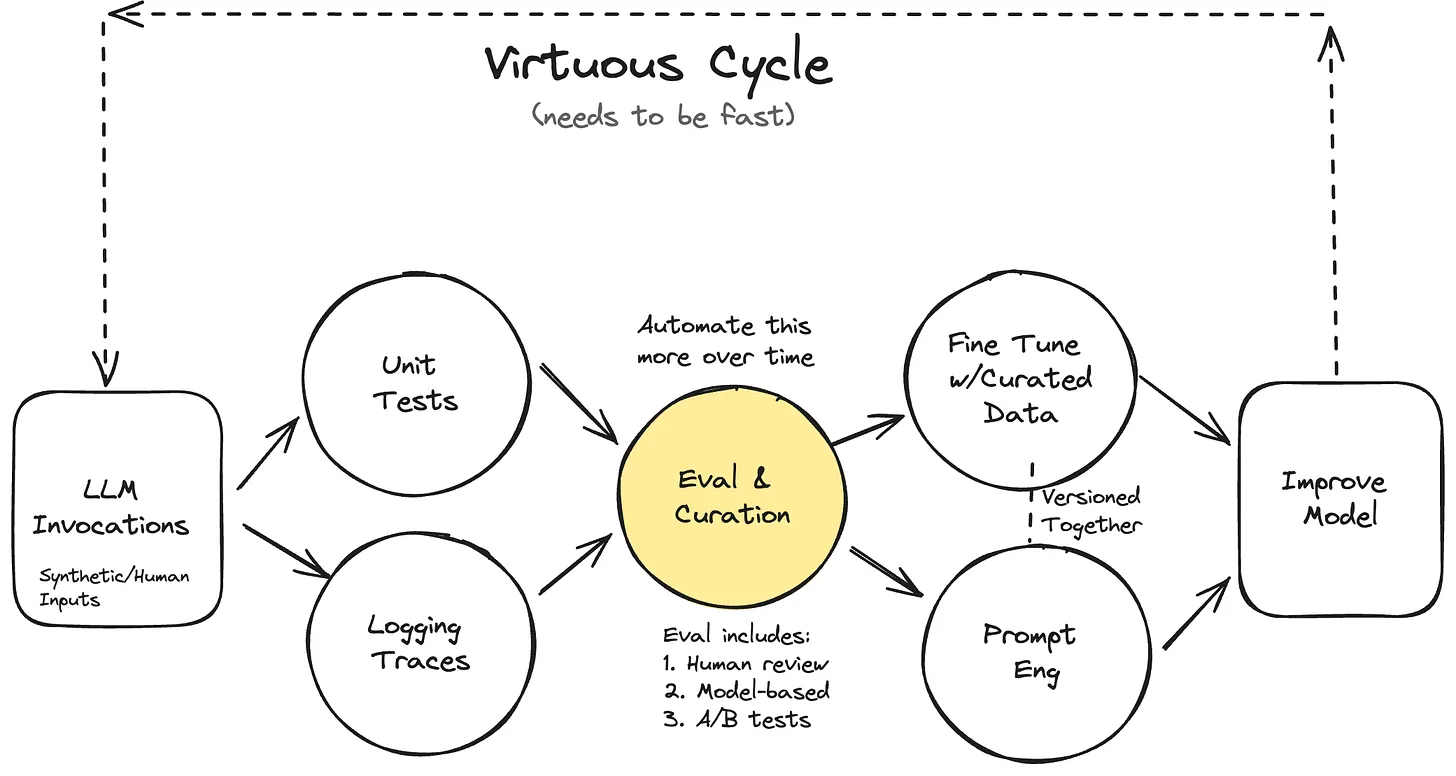 “From Hamel Hussain’s blog [2]”
“From Hamel Hussain’s blog [2]”
Every few weeks, you hear about problematic AI systems deployed to the world. There was the recent fiasco with a chatbot released by WHO which could have ended up harming more people than helping them. Another case a few months back was with the UK-based logistics company DPD. They deployed a chatbot for customer support, which somehow ended up bad-mouthing the company itself [5]. Apart from these very big and famous cases, every day a smaller business tries out a use-case with LLMs get to a PoC stage but then end up playing whack-a-mole with issues till they give up and abandon it. Its actually very similar to the early days of when machine learning systems were being adopted by companies.
To fix all these issues, we need model evaluation, also called in the LLM world as evals. Without having a robust evaluation system in place, your LLM-powered product will never see the light of production [2]. It is a mix of tracing logs, unit-tests, and dataset curation. Evaluations have 3 levels: unit tests being the most basic checks, model and human eval which involves more subjectivity, and A/B testing for really mature systems. At the first level, using basic checks and balances using regex or assertions, the basic issues can be filtered out. Harmful trigger words, PII (personally identifiable information), undesired output formats can all be tested for, and fixed this way. On the second level, assessment of outputs on a binary or ordinal scale by both another LLM and humans gives more depth to the evaluation. It is important to ensure 2 things. One, that you are using a more powerful LLM to evaluate the one you are using in the system. And two, that there is alignment between human and model evals. If there is large-scale disagreement between the two, you need to investigate the eval system itself. The final level of A/B testing is the same as a traditional product’s A/B testing, and hence comes into play when you already have a healthy user base.
All this is great. I can evaluate an LLM-based product more fully. But, how is this helping me pick the LLM compared to benchmarks. Firstly, benchmarks are general. Eval systems like these are not only specific to your task, but your product as well. You can evaluate how well the LLM fits into your whole use-case. Secondly, as I mentioned before, prompt-LLM fit can only be discovered through such a system… And third, many of these can be low-tech solutions which brings involvement of broader set of stakeholders. Many “business” people can directly contribute to your eval and dataset curation. Sounds amazing doesn’t it? But as with all things, there’s a catch.
… but its not as easy
Evals are the best thing since sliced bread, but the challenge is that they are hard to do, which seems counter-intuitive. Allow me to explain. First things first, the infrastructure of evals is still in the beginning stages. Hell even LangSmith was in closed beta up until a few months back. The whole LLMOps field seems completely new to even the industry folks, because it is. Yes, there are some tools and a few methods that people have figured out works, but all in all there’s still a long way to go.
Speaking of infrastructure, one of the most important components of testing is model evals, where another LLM evaluates yours. A big problem that we recently found out as a community is that these models are biased towards their own outputs [6]. It makes the whole auto-eval thing a bit more tricky. There is a handy workaround of measuring alignment between human and model evals, but that would require a lot more human effort, which can become expensive.
People are needed to do the most important job of this whole process though, and that’s curating the datasets. Again, its not that easy. First, we have the problem of standardising the workflow and finding the right tool for the job. But, the second part is the larger problem, which is to create eval datasets for agentic workflows. If you have been following the space, agents have taken over. The thing is that some of them are damn useful, but they are a pain to test. Finally, we have the synthetic data route but to be really effective in that game you need a really good starting dataset. And that give us a cold-start problem.
What is left to do
For all the slander I have dished out to benchmarks, a lot of them are genuinely helpful to get a general feel for the performance of LLMs. There’s a reason both academia and industry have been using them for the last few years. What I wanted to highlight is that they are not flawless as many make them out to be. Furthermore, they are not very useful to measure the ability on specific domains or tasks. For this part, evals are a better choice and generally a good practice when building complex LLM-based workflows for your product. It is still a nascent area of research so the tools and infrastructure around it is new and constantly improving, which can make it a challenge to adopt. But it is still worth it, especially if you want to take your PoC to production. In an era where LLMs hold both immense promise and peril, the commitment to continual, context-aware evaluation will separate the leaders from the laggards, paving the way for AI systems that are not only powerful but trustworthy and aligned with human values.
References
- Zhang, H. et al. (2024). A Careful Examination of Large Language Model Performance on Grade School Arithmetic. arXiv preprint
- Hamel Hussain (2024). Your AI Product Needs Evals. Link
- SmartGPT. Link
- Moghaddam, Shima R. Honey, Christopher J. (2023). Boosting Theory of Mind Performance in Large Language Models. Link
- Jane Clinton (2024). DPD AI chatbot swears, calls itself ‘useless’ and criticises delivery firm. Link
- Panickssery, A., et. al. (2024). LLM Evaluators Recognize and Favor Their Own Generations. arXiv preprint